
I suspect that anyone reading my blog will notice that unlike other blogs, I tend to post about things I’m going to do, not things that I’ve done. My latest interest is in neural networks. I think that I have a good grasp of how they work aside from things like how to pick an activation function. And I even feel comfortable saying that I understand how they are used for different situations. I have a very good understanding of evolution algorithms for training the networks.
Neural networks are still perplexing in some ways. For instance, how would I teach a network using the reinforcement method? Biological networks like our brains are more complex than computer neural networks and can learn using reinforcement; Success at something strengthens the pathways that led to the success. Since learning involves trying to do something over and over and seeing the various outcomes, there must be some variable to the process, and it’s this variable that I don’t quite understand. I’ll explain how to evolve a network and then explain why reinforcement training is not at all the same (in my mind).
Neural Network Evolution
A neural network in a computer consists of nodes that act (slightly) like biological neurons. The neurons are connected together in a network. The network can be designed in numerous ways to achieve varying results but simple networks are all fairly similar to each other with a set of input neurons, connections to a set of internal neurons, and connections from those to output neurons. It is the internal neurons that make the networks interesting. Now assume that you have a network that is good at whatever task it is designed and trained for; If you feed it a set of inputs, you will get outputs that are a useful result; Input information about the shape of the road ahead and you will get output that can steer a car properly down the road. This all works because the various neural connections have varying strengths.
The easiest way to make a successful network is to design it and program all of the connections ahead of time. Some of the human brain works this way and we don’t need to learn everything our brain does, or at least it seems that way. The next easiest way to get to having a good network is to create a lot of copies of the network and then make random small changes. Then use the network for the designed task and throw out all of the unsuccessful variations, and even some that are successful if they are not best. Then take the most successful variations and repeat the process by copying them and mutating them. Keep an unmodified copy so you don’t lose progress. This is evolution by “natural” selection. The selection is “natural” because there is no thought given to it and it is simply the environment and network that determine which mutations are kept and which are thrown out. This is how biological evolution works.
Neural Network Reinforcement Training
Now we are on to a subject I know nothing about. I imaging the reinforcement training as a series of attempts followed by adjustments to the network based on the results. But one thing that seems to still be required is variation in the network. Imagine you are trying to play a guitar and you read the music and move your fingers to make some sounds. You have some way to detect that your sounds are not what you expect, maybe by comparing the memory of the sounds you just made to the memory of sounds made by a professional you listened to. Or maybe you simply play back the memory of what you just played and observe that the lengths of the various notes are not as expected. Now what? Your brain is now going to either strengthen the network or weaken it. But how does the brain know what parts of the network contributed to the successful parts of the practice and what parts contributed to failure? That’s the part that makes no sense to me. The first thing to do is ignore the human brain because it’s too complex and does things we can probably not do in our neural network. What do we do then? One idea is to “try” something different each time and just reinforce the successes. Instead of mutating a bunch of child networks from a “good” parent, we take the one network and perform some math on it base don outcome; Maybe the values of all connections are exponentially increased so strong connections get much stronger but weak connections hardly get stronger at all. Then, to keep the connections within a good numeric range, we linearly lower all connection strengths. This is something that scientists think happens in human brains while we sleep; Stronger connections are made stronger as we learn things during the day then all connections are lowered during the night. The effect is to negate any false positives from training. Another way to say that is to say that some of what we did wrong was also rewarded and considered good but since it wasn’t a lot, it gets set back to zero the next day as all connection strengths are lowered. The connections that contributed to a lot of success are not lowered to zero and voila, we have changes our network and learned something!
If it was not obvious, both techniques require some sort of variation in the network during training. With evolution, random changes that have good results are simply kept and the changes that are bad are thrown out completely. With reinforcement, and this is just how it seems to me to work, random changes are all kept but those that pass on high values through their connections are kept strong while weak connections are “lost”. It’s still not right since these simulated neural networks are mathy and maybe low strength connections are important too. Maybe any connection that has a low strength needs to be lowered exponentially and then during the “sleep” portion of the training, all connections are moved a bit towards a mid-value.
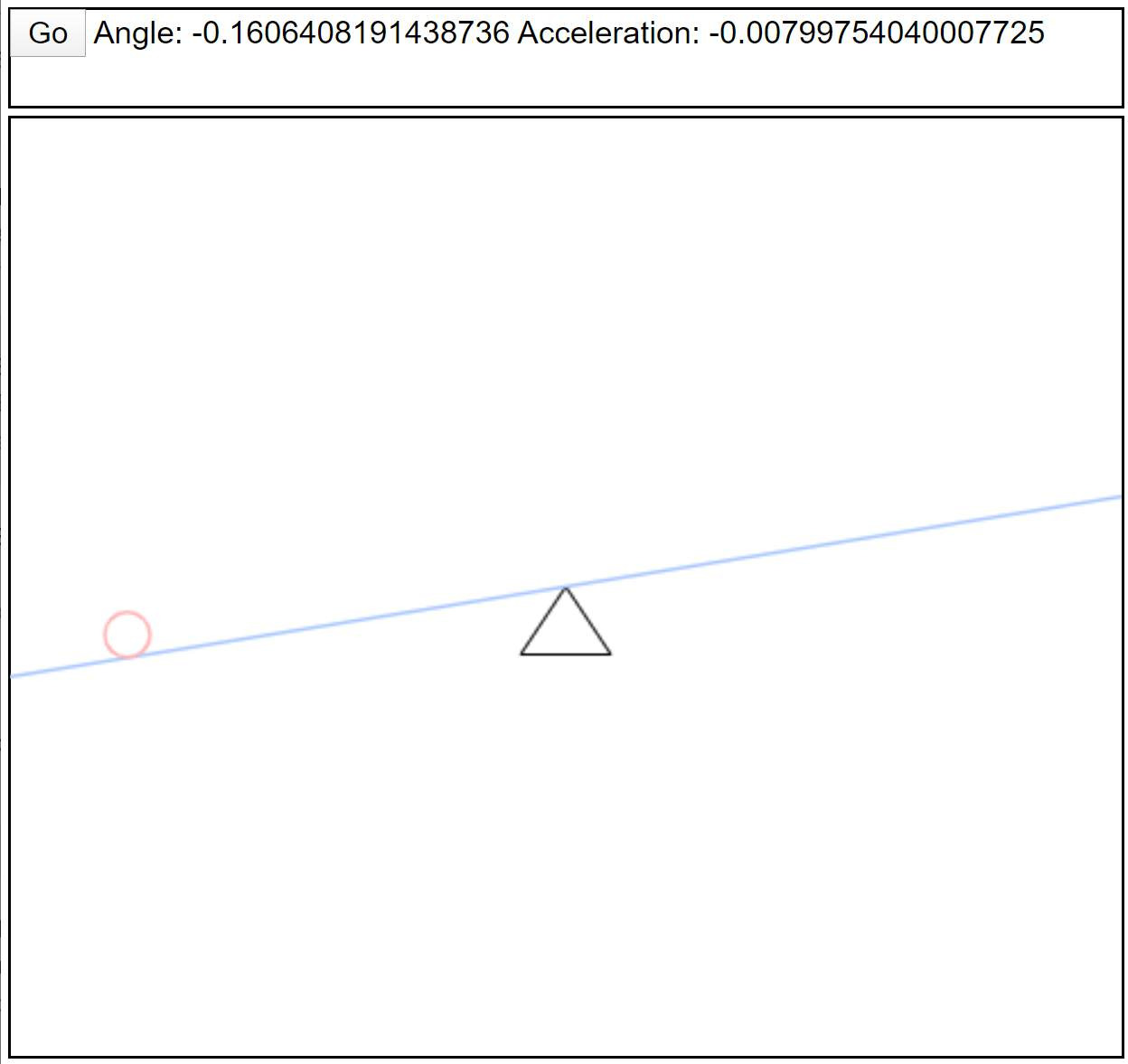
I have started writing a JavaScript implementation of a balancing ball neural network. It is not even close to done while I write this and may not work if you visit the site. But it’s here: https://www.rectorsquid.com/neural.html
The end result of this will be a web page that has a pivot and a beam. On the beam is a ball. The neural network will attempt to balance the ball in the middle of the beam. I’ll add some way to put the ball on the beam and give it some movement to see the working network in action. I will also have a way to place the ball and give it speed randomly for training. The neat thing is that every time the network runs manually from a user placing the ball somewhere on the beam, it will still learn using a reinforcement method.
There are still tons of questions. For instance, how do I determine if the network was more of less successful give that the ball might be placed at locations that require a different amount of time to resolve? Is the time to stability enough of a measure? What about keeping track of deviation from the center and treating any training where the ba result? We’ll see.